Pemodelan SARIMAX (Seasonal Autoregressive Integrated and Moving Average with Exogenous Variable) dengan R
 |
| Seasonal ARIMA dengan variabel eksogen (SARIMAX) di R |
Hai teman-teman, jumpa lagi dengan blog jokoding.com, kali ini kita akan melanjutkan belajar bersama mengenai pemodelan statistik. Jenis pemodelan kita kali ini saya angkat karena ada sebuah permintaan (request) dari sahabat kita di LinkedIn beberapa waktu lalu ketika saya coba sharing terkait model Autoregressive Intergrated and Moving Average (ARIMA).
Model kita kali ini disebut sebagai SARIMAX. Apa kepanjangannya? Ya benar, Seasonal Autoregressive Integrated and Moving Average with Exogenous Regressor Model. Jadi, model ini merupakan model yang masih sekeluarga dari ARIMA. Model ini merupakan pengembangan ARIMA mengingat adanya dugaan faktor lain yang mempengaruhi sebuah variabel selain oleh masa lalu dirinya sendiri. Di dalam model SARIMAX, ini saya langsung pakai Seasonal karena data yang akan kita gunakan dalam praktik merupakan data yang memiliki pola musiman.
Setidak ada 2 istilah yang kita kenal di dalam pemodelan ini, yaitu variabel endogen dan variabel eksogen. Kendati ada istilah itu, namun esensinya sama dengan model regresi biasanya, variabel endogen mudahnya merupakan variabel dependen atau variabel yang dipengaruhi oleh variabel lain baik secara langsung maupun secara tidak langsung. Sedangkan variabel eksogen sederhananya merupakan variabel independen atau variabel yang memberikan pengaruh (memengaruhi) variabel lain secara langsung.
Kedua sebutan variabel ini, kelak akan kita bahas lebih lanjut dalam analasis Path (Path Analysis) atau bentuknya pengembangannya, yaitu Structural Equations Model (SEM).
Baik, kali ini yang akan kita praktikkan adalah pemodelan SARIMAX dengan variabel eksogen adalah jumlah kunjungan wisatawan ke Jawa Timur triwulanan sejak 2016 sampai 2021. Sedangkan variabel endogennya adalah laju pertumbuhan lapangan usaha penyediaan akomodasi dan makan minum triwulanan 2016 - 2021. Kenapa kita bahas kedua variabel tersebut? Karena selama pandemi Covid-19, sektor yang paling terdampak adalah sektor pariwisata dan untuk menguatkan pembentukan variabel eksogen dan endogennya, berikut beberapa hasil penelitian terkait dengan wisatawan dan dampaknya terhadap perekonomian suatu wilayah.
Penelitian terkait pengaruh jumlah wisatawan terhadap pertumbuhan sektor penyediaan akomodasi dan makan minum telah banyak dilakukan. Seperti hasil penelitian Yoga (2012) yang menggunakan analisis Path, ia membuktikan bahwa jumlah kunjungan wisatawan mancanegara berpengaruh positif dan signifikan terhadap Produk Domestik Regional Bruto (PDRB) Bali. Demikian halnya dengan penelitian yang dilakukan oleh Damayanti (2013), bahwa wisatawan mancanegara berpengaruh positif dan signifikan terhadap PDRB industri pariwisata. Dilanjutkan dengan penelitian Asworowati (2016) yang membuktikan bahwa pengaruh pengeluaran wisatawan mancanegara berpengaruh terhadap perekonomian daerah penelitiannya. Hasil serupa juga diperoleh dari penelitian Yoel (2008). Dengan menggunakan regresi linier dengan metode estimasi Ordinary Least Square (OLS), ia menyimpulkan bahwa jumlah wisatawan berpengaruh signifikan dan positif terhadap PDRB sektor pariwisata.
Dari beberapa hasil penelitian ini, data yang akan kita gunakan telah saya siapkan sebelumnya, jadi teman-teman yang berminat mempratikkan bisa mengunduhnya dulu pada tautan berikut. Setelah diunduh, pemodelan SARIMAX dengan menggunakan R dapat mengikuti beberapa code berikut:
Code:
#Install dan aktivasi package utama pemodelan
install.packages("forecast")
install.packages("fpp2")
library(fpp2)
library(forecast)
#import data
library(readxl)
dataku <- read_excel("C:/Users/Joko Ade/Downloads/arimaxku.xlsx")
#membentuk data Triwulanan
data_ts <- ts(dataku, start = c(2016,1), frequency = 4)
#Ringkasan data
summary(data_ts)
Hasil:
lpeqtoq wisatawan
Min. :-18.410 Min. :0.000000
1st Qu.: -1.298 1st Qu.:0.004026
Median : 1.670 Median :0.579726
Mean : 1.099 Mean :0.481412
3rd Qu.: 3.308 3rd Qu.:0.732320
Max. : 9.710 Max. :1.000000
Code:
#Plot data
autoplot(data_ts, facets = T) +
xlab("Tahun") + ylab("") +
ggtitle("Laju Pertumbuhan Lapus Penyediaan Akomodasi dan Makan Minum \ndan Jumlah Wisawatan Datang ke Jawa Timur Q1/2016 - Q4/2021")
Hasil:
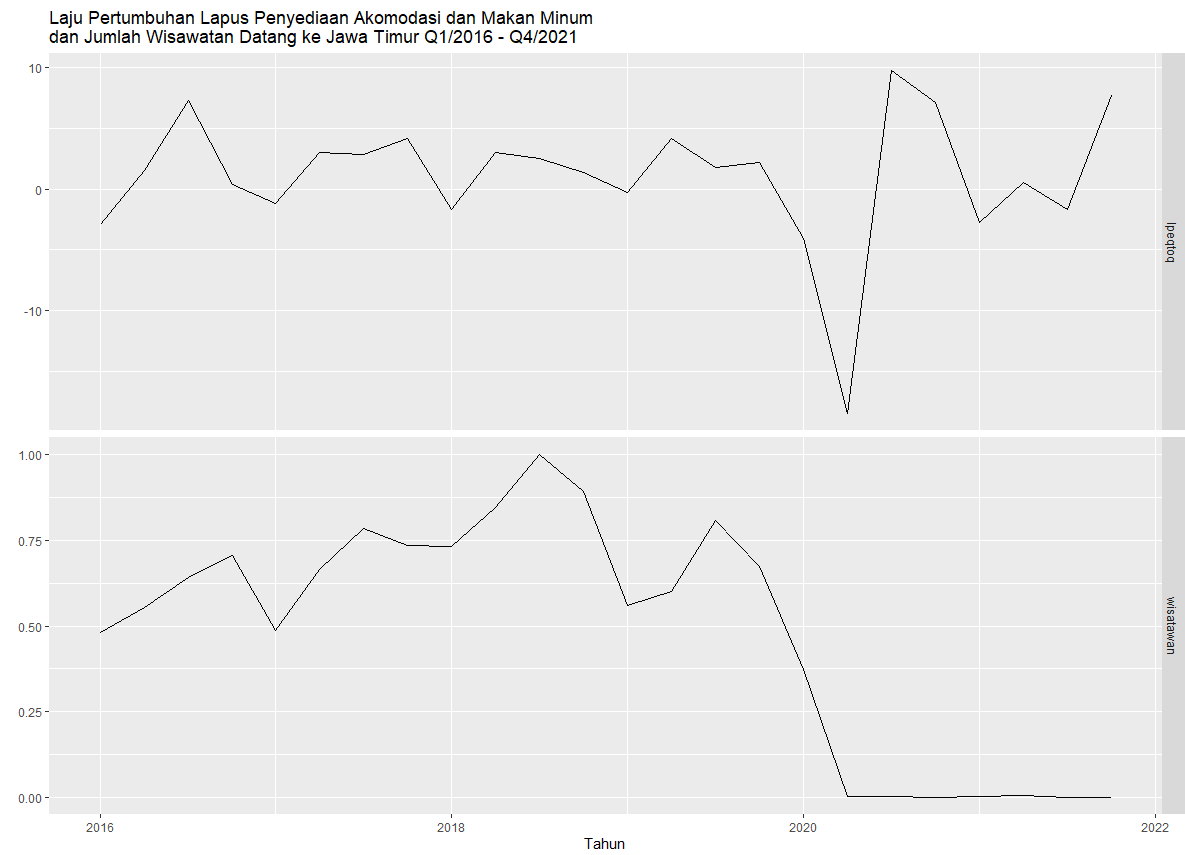 |
| Visualisasi 1 |
Code:
#Mendiagnosa pola ACF
ggAcf(data_ts) + ggtitle("Plot ACF")
#Mendiagnosa pola PACF
ggPacf(data_ts) + ggtitle("Plot PACF")
Hasil:
 |
| Plot ACF untuk menentukan order MA |
 |
| Plot PACF untuk menentukan order AR |
Code:
#Melihat pola dekomposisi masing-masing variabel
lpe_akmamin <- dataku$lpeqtoq %>% ts(., frequency = 4, start = c(2016,1))
lpe_akmamin_dekom <- stl(lpe_akmamin, s.window = "periodic")
autoplot(lpe_akmamin_dekom)
Hasil:
 |
| Dekomposisi runtun waktu untuk melihat pola data trend dan musiman |
Code:
#Pemodelan SARIMAX dengan karena ada pola musiman pada dekomposisi
attach(dataku)
library(lmtest)
#Model SARIMAX1
sarimax1 <- auto.arima(lpeqtoq, xreg = wisatawan, trace = T, seasonal = TRUE, stepwise = F, approximation = F)
#Model SARIMAX2
sarimax2 <- arima(lpeqtoq, order = c(2, 0, 0), xreg = wisatawan, seasonal = list(order = c(0, 0, 1), period = 4), include.mean = T)
#Model SARIMAX3
#Model SARIMAX tanpa drift karena drift tidak signifikan
sarimax3 <- arima(lpeqtoq, order = c(2, 0, 0), xreg = wisatawan, seasonal = list(order = c(0, 0, 1), period = 4), include.mean = F)
Hasil:
ARIMA(0,0,0) with zero mean : 152.4839
ARIMA(0,0,0) with non-zero mean : 155.1011
ARIMA(0,0,1) with zero mean : 153.2841
ARIMA(0,0,1) with non-zero mean : 156.1776
ARIMA(0,0,2) with zero mean : Inf
ARIMA(0,0,2) with non-zero mean : Inf
ARIMA(0,0,3) with zero mean : Inf
ARIMA(0,0,3) with non-zero mean : Inf
ARIMA(0,0,4) with zero mean : Inf
ARIMA(0,0,4) with non-zero mean : Inf
ARIMA(0,0,5) with zero mean : Inf
ARIMA(0,0,5) with non-zero mean : Inf
ARIMA(1,0,0) with zero mean : 154.7761
ARIMA(1,0,0) with non-zero mean : 157.6731
ARIMA(1,0,1) with zero mean : Inf
ARIMA(1,0,1) with non-zero mean : Inf
ARIMA(1,0,2) with zero mean : Inf
ARIMA(1,0,2) with non-zero mean : Inf
ARIMA(1,0,3) with zero mean : Inf
ARIMA(1,0,3) with non-zero mean : Inf
ARIMA(1,0,4) with zero mean : Inf
ARIMA(1,0,4) with non-zero mean : Inf
ARIMA(2,0,0) with zero mean : 153.658
ARIMA(2,0,0) with non-zero mean : 156.8756
ARIMA(2,0,1) with zero mean : Inf
ARIMA(2,0,1) with non-zero mean : Inf
ARIMA(2,0,2) with zero mean : Inf
ARIMA(2,0,2) with non-zero mean : Inf
ARIMA(2,0,3) with zero mean : Inf
ARIMA(2,0,3) with non-zero mean : Inf
ARIMA(3,0,0) with zero mean : 156.2828
ARIMA(3,0,0) with non-zero mean : 159.8826
ARIMA(3,0,1) with zero mean : Inf
ARIMA(3,0,1) with non-zero mean : Inf
ARIMA(3,0,2) with zero mean : Inf
ARIMA(3,0,2) with non-zero mean : Inf
ARIMA(4,0,0) with zero mean : 159.251
ARIMA(4,0,0) with non-zero mean : 163.308
ARIMA(4,0,1) with zero mean : Inf
ARIMA(4,0,1) with non-zero mean : Inf
ARIMA(5,0,0) with zero mean : 162.3275
ARIMA(5,0,0) with non-zero mean : 166.8758
Best model: Regression with ARIMA(0,0,0) errors
Code:
#Ringkasan Model
summary(sarimax1)
summary(sarimax2)
summary(sarimax3)
Hasil:
Series: lpeqtoq
Regression with ARIMA(0,0,0) errors
Coefficients:
xreg
2.4191
s.e. 1.8351
sigma^2 estimated as 29.01: log likelihood=-73.96
AIC=151.91 AICc=152.48 BIC=154.27
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set -0.06541324 5.272847 3.399757 79.78266 115.5155 0.6443709 -0.1138176
Call:
arima(x = lpeqtoq, order = c(2, 0, 0), seasonal = list(order = c(0, 0, 1), period = 4),
xreg = wisatawan, include.mean = T)
Coefficients:
ar1 ar2 sma1 intercept wisatawan
0.0603 -0.9668 -1.0000 -0.4202 2.5906
s.e. 0.0927 0.0776 0.2336 0.7965 1.4145
sigma^2 estimated as 14.55: log likelihood = -69.38, aic = 150.77
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.167009 3.815091 2.996547 39.8852 130.295 0.5679487 -0.2962499
Call:
arima(x = lpeqtoq, order = c(2, 0, 0), seasonal = list(order = c(0, 0, 1), period = 4),
xreg = wisatawan, include.mean = F)
Coefficients:
ar1 ar2 sma1 wisatawan
0.0648 -0.9609 -0.9998 1.8707
s.e. 0.0950 0.0834 0.2384 0.3762
sigma^2 estimated as 14.71: log likelihood = -69.52, aic = 149.04
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.1524059 3.835937 2.949479 36.03903 128.7071 0.5590278 -0.2812725
Code:
#Uji Signifikansi
coeftest(sarimax2)
rbind(coeftest(sarimax1), coeftest(sarimax2), coeftest(sarimax3))
#Uji asumsi nonautokorelasi Ljung-Box
rbind(checkresiduals(sarimax1),checkresiduals(sarimax2),checkresiduals(sarimax3))
#Uji Normalitas Residual model SARIMAX
jarque.bera.test(sarimax2$residuals)
rbind(jarque.bera.test(sarimax1$residuals),jarque.bera.test(sarimax2$residuals),jarque.bera.test(sarimax3$residuals))
#AIC dan BIC
cbind(rbind(Model1 = AIC(sarimax1),Model2 = AIC(sarimax2), Model3 = AIC(sarimax3)),
rbind(Model1 = BIC(sarimax1),Model2 = BIC(sarimax2), Model3 = BIC(sarimax3)))
Hasil:
Estimate Std. Error z value Pr(>|z|)
xreg 2.41909032 1.83512782 1.3182135 1.874322e-01
ar1 0.06029365 0.09272973 0.6502084 5.155576e-01
ar2 -0.96678932 0.07759928 -12.4587406 1.253342e-35
sma1 -0.99999027 0.23360054 -4.2807703 1.862475e-05
intercept -0.42015063 0.79645614 -0.5275251 5.978290e-01
wisatawan 2.59062370 1.41445695 1.8315324 6.702112e-02
ar1 0.06477122 0.09498716 0.6818944 4.953057e-01
ar2 -0.96092361 0.08337186 -11.5257549 9.785080e-31
sma1 -0.99982246 0.23835525 -4.1946736 2.732649e-05
wisatawan 1.87072751 0.37623269 4.9722620 6.617618e-07
Ljung-Box test
data: Residuals from Regression with ARIMA(0,0,0) errors
Q* = 6.0169, df = 4, p-value = 0.1979
Model df: 1. Total lags used: 5
Ljung-Box test
data: Residuals from ARIMA(2,0,0)(0,0,1)[4] with non-zero mean
Q* = 7.5277, df = 3, p-value = 0.05685
Model df: 5. Total lags used: 8
Ljung-Box test
data: Residuals from ARIMA(2,0,0)(0,0,1)[4] with zero mean
Q* = 6.3942, df = 3, p-value = 0.09393
Model df: 4. Total lags used: 7
statistic parameter p.value method
[1,] 6.016899 4 0.1978898 "Ljung-Box test"
[2,] 7.52767 3 0.05685173 "Ljung-Box test"
[3,] 6.394197 3 0.09392982 "Ljung-Box test"
data.name
[1,] "Residuals from Regression with ARIMA(0,0,0) errors"
[2,] "Residuals from ARIMA(2,0,0)(0,0,1)[4] with non-zero mean"
[3,] "Residuals from ARIMA(2,0,0)(0,0,1)[4] with zero mean"
Uji normalitas
statistic parameter p.value method data.name
[1,] 22.8638 2 1.084396e-05 "Jarque Bera Test" "sarimax1$residuals"
[2,] 6.134182 2 0.0465564 "Jarque Bera Test" "sarimax2$residuals"
[3,] 5.410167 2 0.06686473 "Jarque Bera Test" "sarimax3$residuals"
AIC dan BIC
AIC BIC
[,1] [,2]
Model1 151.9124 154.2685
Model2 150.7675 157.8359
Model3 149.0419 154.9322
Code:
#Model Terpilih SARIMAX3
#Model SARIMAX tanpa drift karena drift tidak signifikan
sarimaxku3 <- arima(lpeqtoq, order = c(2, 0, 0), xreg = wisatawan, seasonal = list(order = c(0, 0, 1), period = 4), include.mean = F)
#Peramalan
datax <- dataku$wisatawan
datay <- dataku$lpeqtoq
xreg1 <- rep(mean(datax),4)
fc <- forecast(sarimaxku3, xreg = xreg1, h = 4)
poin_fc <- fc$mean
pred <- sarimaxku3$fitted
pred <- ts(pred, start = c(2016,1), frequency = 4)
pesimis <- as.data.frame(fc$lower)[2]
optimis <- as.data.frame(fc$upper)[2]
poin_fc <- ts(fc$mean, start = c(2022,1), frequency = 4)
line_ts <- ts(dataku$lpeqtoq, start = c(2016,1), frequency = 4)
a <- plot(line_ts, col = "blue", type = "l", xlim = c(2016.1, 2023.2), pch = 19,
ylab = "Pertumbuhan (persen)", xlab = "Periode", ylim = c(-20,20))
b <- lines(pred, col = "red", type = "b")
c <- lines(poin_fc, col = "steelblue", type = "b")
d <- lines(ts(pesimis$`95%`, start = 2022.1, frequency = 4), col = "grey", type = "b")
e <- lines(ts(optimis$`95%`, start = 2022.1, frequency = 4), col = "grey", type ="b")
text(2022.1,15, c("Skenario\n Optimis"), cex = 0.8)
text(2022.1,-15, c("Skenario\n Pesimis"), cex = 0.8)
abline(v =2020.2, col = 5, lty=2)
text(2020.1, 15, c("Kebijakan PSBB"), cex = 0.8)
legend(2016.1,-5, legend = c("Data Aktual", "Prediksi dari SARIMAX(2,0,0)[4]", "Forecast", "Upper Forecast 95%",
"Lower Forecast 95%"), col = c("blue", "red", "steelblue", "grey", "grey"),
lty = 1, cex = 0.8, box.col = "white", horiz = F)
Hasil:
 |
| Plot hasil peramalan dan memprediksi skenario optimis dan pesimis |
Demikian sedikit ulasan mengenai pemodelan SARIMAX dengan R. Semoga sedikit banyak membantu pemahaman teman-teman, jangan lupa share dan terus ikuti unggahan selanjutnya. Selamat mempraktikkan!
Komentar
Posting Komentar