 |
| Visualisasi matriks korelasi dan uji signifikansi korelasi variabel |
Hai teman-teman, kembali lagi kita akan belajar bersama-sama. Kalau kemarin kita sedikit serius membahas bagaimana pemodelan ARIMA dengan menggunakan R secara cukup urut dan rinci, kali ini kita break dulu untuk membahas visualisasi data.
Visualisasi yang akan kita ulas kali ini adalah hasil korelasi antar variabel yang kita gunakan dalam penelitian. Secara sederhana, korelasi sendiri merupakan besarnya hubungan keeratan antara suatu variabel dengan variabel lainnya yang ditunjukkan oleh besar dan arah. Mirip dengan pengertian besaran vektor yang juga ditunjukkan oleh besar dan arahnya, korelasi biasanya digunakan sebagai awalan deskripsi variabel penelitian untuk melihat seberapa besar keterkaitan antar variabel. Aspek yang perlu ditekankan sebagai pembeda antara korelasi dan regresi yaitu tujuannya. Kalau regresi menunjukkan hubungan sebab-akibat variabel yang digunakan, sedangkan kalau korelasi tidak menunjukkan sebab-akibat.
Seperti yang kita ketahui, korelasi yang populer hingga saat ini adalah korelasi Spearman atau disebut pula korelasi Rank Spearman dan korelasi Pearson atau disebut juga korelasi moment product. Perbedaan dari dua jenis korelasi ini umumnya pada jenis penelitiannya, kalau korelasi Pearson biasa digunakan untuk data-data parametrik atau data kontinu serta diksrit. Sedangkan korelasi Spearman biasanya digunakan untuk data-data nonparametrik baik kontinu maupun diskrit.
Adapun persamaan dari kedua jenis korelasi tersebut adalah pada besarnnya. Baik korelasi Spearman maupun korelasi Pearson, keduanya memiliki nilai korelasi pada selang interval 0 sampai 1. Semakin menuju 1, korelasi antara dua variabel dikatakan semakin kuat dan dalam praktiknya, para ahli statistika kemudian melakukan pengelompokan kekuatan korelasi menjadi beberapa tingkatan.
Untuk korelasi yang bernilai 0 dikatakan bahwa kedua variabel tidak berkorelasi. Bila nilai korelasi 0,01 - 0,20 dikatakan berkorelasi sangat rendah, korelasi 0,21 - 0,40 dikatakan berkorelasi rendah, 0,41 - 0,60 dikatakan agak rendah, 0,61 - 0,80 dikatakan korelasinya cukup, 0,81 - 0,99 dikatakan korelasinya tinggi, dan 1 berkorelasi sangat tinggi (sempurna). Selain pengelompokkan seperti ini, pengelompokan lainnya juga banyak dilakukan namun esensinya sama, semakin menuju 1 maka korelasi dua variabel dikatakan semakin kuat.
Perihal arah korelasi, sebenarnya ia hanya menunjukkan arah kecenderungan dalam interpretasinya. Bukan menunjukkan sebab dan akibat. Dalam hukum permintaan (product demand) misalkan, ketika harga barang semakin tinggi (mahal), permintaan konsumen akan cenderung menurun. Pada kasus ini dikatakan korelasinya memiliki arah negatif. Atau pada kasus lain misalkan, semakin tinggi lama pendidikan seseorang, maka ada kecenderungan konsumsi mereka semakin tinggi (banyak). Pada kasus ini dikatakan korelasinya memiliki arah yang positif.
Lantas? Bagaimana penerapan visualisasi sekaligus uji signifikansi korelasi banyak variabel dengan R? Untuk datanya kali ini kita akan men-generate data sendiri kemudian kita lakukan visualisasi matriks korelasi berikut dengan uji signifikansi korelasinya dengan menggunakan beberapa code berikut:
Code:
#Membuat Matriks Korelasi
#Membuat Data Frame
df <- data.frame(lamapendidikan=c(4, 5, 5, 6, 7, 8, 8, 10),
pengeluaran=c(12, 14, 14, 13, 15, 16, 15, 12),
pendapatan=c(22, 25, 26, 27, 29, 32, 39, 40))
#Menampilkan Data Frame
df
Hasil:
lamapendidikan pengeluaran pendapatan
1 4 12 22
2 5 14 25
3 5 14 26
4 6 13 27
5 7 15 29
6 8 16 32
7 8 15 39
8 10 12 40
Code:
#Membuat Matriks Korelasi
cor(df)
Hasil:
lamapendidikan pengeluaran pendapatan
lamapendidikan 1.0000000 0.1780213 0.9404385
pengeluaran 0.1780213 1.0000000 0.1646659
pendapatan 0.9404385 0.1646659 1.0000000
Terlihat bahwa korelasi antara pendapatan dan lama pendidikan arahnya positif dan cukup tinggi 0,9404385 sedangkan korelasi antara pengeluaran dan lama pendidikan sangat rendah dan positif 0,1780213, demikian halnya dengan korelasi pendapatan dan pengeluaran.
Code:
#Plot Matriks Korelasi
library(corrplot)
corrplot(cor(df))
Hasil:
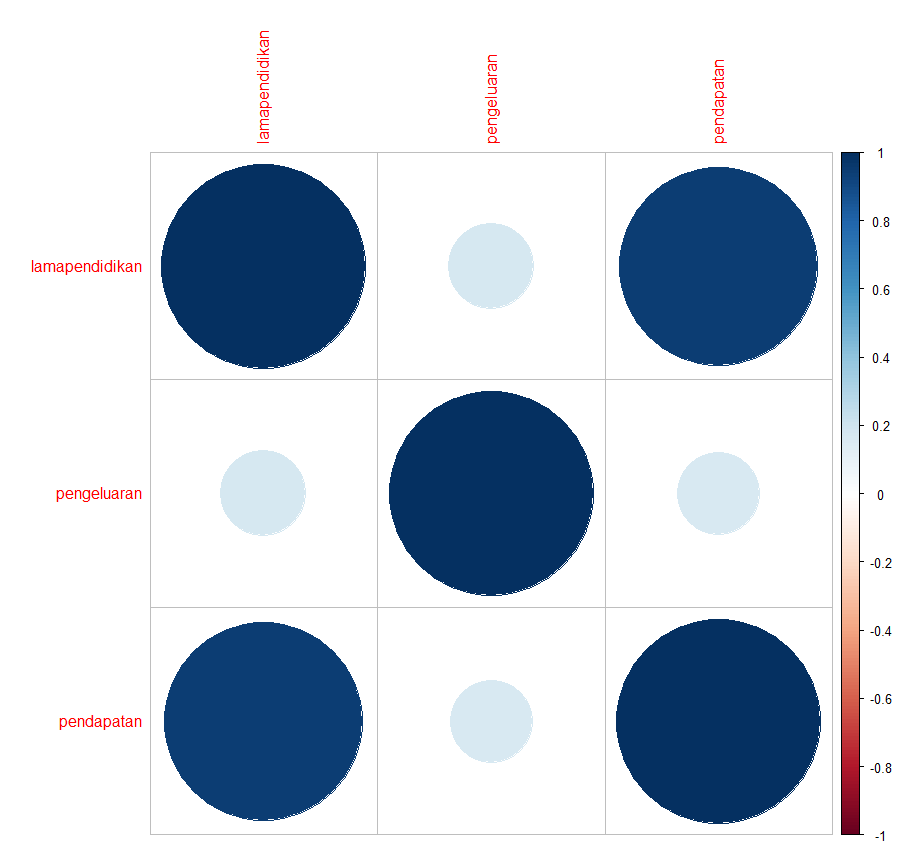 |
| visualisasi 1 |
Code:
#Mengcustome bentuk lain matriks korelasi
par(mfrow=c(2, 2))
corrplot(cor(df), method = "circle")
corrplot(cor(df), method = "pie")
corrplot(cor(df), method = "color")
corrplot(cor(df), method = "number")
Hasil:
 |
| Visualisasi 2 |
Code:
#Plot matriks korelasi dengan package ggcorrrplot
par(mfrow=c(1, 1))
library(ggcorrplot)
ggcorrplot(cor(df))
Hasil:
 |
| Visualisasi 3 |
Code:
#Menguji signifikansi korelasi
attach(df)
cor.test(lamapendidikan, pengeluaran)
cor.test(lamapendidikan, pendapatan)
cor.test(pengeluaran, pendapatan)
Hasil:
Pearson's product-moment correlation
data: lamapendidikan and pengeluaran
t = 0.44314, df = 6, p-value = 0.6732
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.6021950 0.7843056
sample estimates:
cor
0.1780213
Pearson's product-moment correlation
data: lamapendidikan and pendapatan
t = 6.776, df = 6, p-value = 0.0005049
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.6989819 0.9894208
sample estimates:
cor
0.9404385
Pearson's product-moment correlation
data: pengeluaran and pendapatan
t = 0.40893, df = 6, p-value = 0.6968
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.6108923 0.7789526
sample estimates:
cor
0.1646659
Terlihat bahwa korelasi variabel yang signifikan hanya lama pendidikan dan pendapatan, selain tinggi dan positif korelasinya juga secara statistik signifikan.
Baik, demikian sedikit pembahasan kita terkait visualisasi korelasi antar variabel dan uji signifikansinya menggunakan R. Jangan lupa share dan bertanya bila ada di kolom komentar. Sampai jumpa pada unggahan selanjutnya. Selamat mempraktikkan!
Komentar
Posting Komentar