 |
| Regresi linier sederhana di R dengan kombinasi bahasa Python |
Bahasa pemrograman dalam dunia Data Science terus bersaing hingga saat ini. Bila dulu, banyak orang yang menggunakan bahasa pemrograman C, C++, Matlab, SAS, Javascript, keperluan memperoleh hingga analisis data saat ini kebanyakan menggunakan bahasa pemrograman R (R Studio sebagai bentuk GUI-nya) dan yang paling baru adalah bahasa Python (Jupyter notebook sebagai salah satu bentuk GUI-nya).
Beberapa bahasa tersebut terlihat bersaing dan banyak-banyakan pengguna (user). Tingkat persaingan tersebut selain dipengaruhi oleh aspek kemudahan dalam coding juga aspek kekuatan atau performanya dalam melakukan pemrosesan data bervolume besar (Big Data). Mengutip data dari komunitas Python Developers tertanggal 27 Februari 2023, berikut adalah data beberapa jenis bahasa pemrograman termasuk olah data menurut jumlah penggunanya:
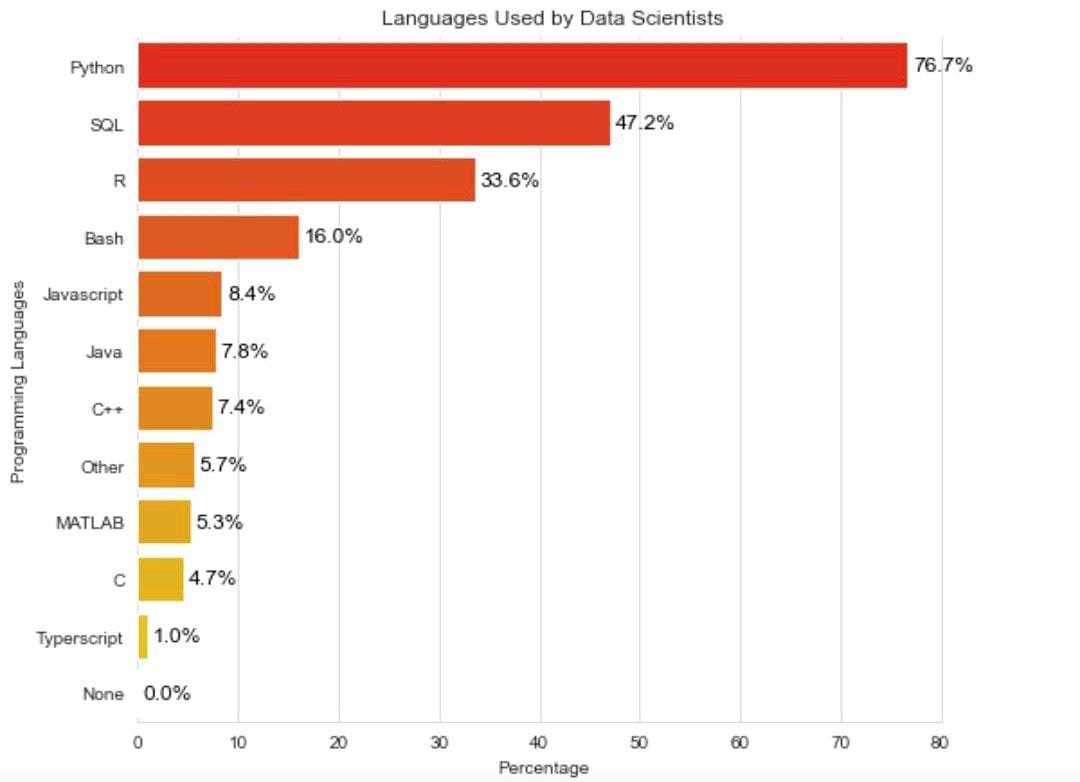 |
| Bar chart jenis bahasa pemrograman dan olah data menurut jumlah pengguna |
Dari gambar tersebut, memang terlihat bahwa Python adalah bahasa pemrograman dan olah data yang saat ini paling banyak jumlah penggunanya, yakni mencapai 76,70 persen. Kemudian diikuti oleh bahasa SQL yang biasanya digunakan untuk manajemen data dan kebutuhan integrasi antar data sebesar 47,20 persen. Pada urutan ketiga, tercatat sebesar 33,60 persen pengguna memakai bahasa R sebagai bahasa pemrograman dan olah datanya.
Terlepas dari kelebihan dan kelamahan masing-masing bahasa, sebenarnya kita dapat mengkombinasikan bahasa pemrograman tersebut untuk melakukan proses memperoleh hingga analisis data dan memvisualisasikannya.
Di kesempatan kali ini, kita akan coba belajar bersama, bagaimana menerapkan kombinasi bahasa pemrograman R dan Python untuk pemodelan analisis regresi linier sederhana dengan pendekatan estimasi Ordinary Least Square (OLS).
Adapun data yang kita gunakan berasal dari unggahan pemodelan regresi linier sederhana dengan R berikut. Setelah datanya telah siap, untuk melakukan pemodelan regresi linier sederhana menggunakan kombinasi bahasa R dan Python dapat mengikuti beberapa langkah berikut:
Pertama kita buat laman markdown R kemudian melakukan coding dengan kode pembuka untuk python seperti gambar di bawah ini:
 |
| Membuat area code pyton baru |
Langkah berikutnya menuliskan code campuran antara R dan python. Untuk code R diawali {r} dan python {python};
 |
| Cara menulis code kombinasi R dan Python |
#Import data
library(readxl)
tender <- read_excel("tender.xlsx")
tender <- tender[c(2, 5)]
#Melihat data
tender
## # A tibble: 9 x 2
## Tender Konstruksi
## <dbl> <dbl>
## 1 133620 6.97
## 2 152677 6.36
## 3 152702 5.22
## 4 132248 6.8
## 5 119219 6.09
## 6 105049 5.76
## 7 68498 -3.26
## 8 96229 2.81
## 9 88631 2.01
#Melihat korelasi antara X dan Y
cor.test(tender$Tender, tender$Konstruksi)
##
## Pearson's product-moment correlation
##
## data: tender$Tender and tender$Konstruksi
## t = 3.8378, df = 7, p-value = 0.006393
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.3512473 0.9616332
## sample estimates:
## cor
## 0.8233138
plot(tender$Tender, tender$Konstruksi, col ="blue",
xlab = "Tender (unit)", ylab = "Pertumbuhan Sektor Konstruksi (%)")

#Transformasi data dari R ke Python
tender_py = r.tender
#Melihat data
tender_py
## Tender Konstruksi
## 0 133620.0 6.97
## 1 152677.0 6.36
## 2 152702.0 5.22
## 3 132248.0 6.80
## 4 119219.0 6.09
## 5 105049.0 5.76
## 6 68498.0 -3.26
## 7 96229.0 2.81
## 8 88631.0 2.01
#Pembutan variabel X dan Y
import statsmodels.api as sm
y = tender_py["Konstruksi"]
x = tender_py["Tender"]
x = sm.add_constant(x)
#Pemodelan regresi linier sederhana OLS
mod = sm.OLS(y, x).fit()
mod.summary()
## <class 'statsmodels.iolib.summary.Summary'>
## """
## OLS Regression Results
## ==============================================================================
## Dep. Variable: Konstruksi R-squared: 0.678
## Model: OLS Adj. R-squared: 0.632
## Method: Least Squares F-statistic: 14.73
## Date: Tue, 28 Feb 2023 Prob (F-statistic): 0.00639
## Time: 11:35:04 Log-Likelihood: -17.955
## No. Observations: 9 AIC: 39.91
## Df Residuals: 7 BIC: 40.30
## Df Model: 1
## Covariance Type: nonrobust
## ==============================================================================
## coef std err t P>|t| [0.025 0.975]
## ------------------------------------------------------------------------------
## const -6.6422 2.931 -2.266 0.058 -13.573 0.289
## Tender 9.395e-05 2.45e-05 3.838 0.006 3.61e-05 0.000
## ==============================================================================
## Omnibus: 0.939 Durbin-Watson: 2.240
## Prob(Omnibus): 0.625 Jarque-Bera (JB): 0.738
## Skew: -0.474 Prob(JB): 0.692
## Kurtosis: 1.966 Cond. No. 5.22e+05
## ==============================================================================
##
## Notes:
## [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
## [2] The condition number is large, 5.22e+05. This might indicate that there are
## strong multicollinearity or other numerical problems.
## """
##
## C:\Users\56848\AppData\Local\R-MINI~1\envs\R-RETI~1\lib\site-packages\scipy\stats\stats.py:1604: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=9
## "anyway, n=%i" % int(n))
#Uji normalitas residual model
from scipy.stats import kstest
kstest(mod.resid, 'norm')
## KstestResult(statistic=0.29425016825979394, pvalue=0.3465698503600516)
#Uji nonautokorelasi residu serial model
#Apabila nilai DW berkisar 1.5 - 2.5 maka nonautokorelasi terpenuhi
from statsmodels.stats.stattools import durbin_watson
durbin_watson(mod.resid)
## 2.2401246784675934
#Uji homoskedastisitas residual model
from statsmodels.compat import lzip
import statsmodels.stats.api as sms
names = ['Lagrange multiplier statistic', 'p-value',
'f-value', 'f p-value']
test = sms.het_breuschpagan(mod.resid, mod.model.exog)
lzip(names, test)
## [('Lagrange multiplier statistic', 0.5975347564447657), ('p-value', 0.43952017704654034), ('f-value', 0.49779953547818107), ('f p-value', 0.503264687351561)]
#Menambahkan variabel baru, yaitu Predicted dan Residuals
tender_py["Predicted"] = mod.predict(x)
tender_py["Residuals"] = mod.resid
tender_py
## Tender Konstruksi Predicted Residuals
## 0 133620.0 6.97 5.911160 1.058840
## 1 152677.0 6.36 7.701525 -1.341525
## 2 152702.0 5.22 7.703874 -2.483874
## 3 132248.0 6.80 5.782264 1.017736
## 4 119219.0 6.09 4.558217 1.531783
## 5 105049.0 5.76 3.226976 2.533024
## 6 68498.0 -3.26 -0.206912 -3.053088
## 7 96229.0 2.81 2.398356 0.411644
## 8 88631.0 2.01 1.684540 0.325460
Dari hasil pemodelan di atas, terlihat bahwa model yang terbentuk konsisten dengan hasil ketika kita melakukan pemodelan menggunakan bahasa R sepenuhnya. Termasuk seluruh uji asumsi klasik juga terpenuhi.
Demikian sedikit sharing kita kali ini. Semoga sedikit memberi manfaat. Nantikan terus unggahan terbaru dan menarik dalam blog sederhana ini. Selamat memahami dan mempraktikkan!
Komentar
Posting Komentar